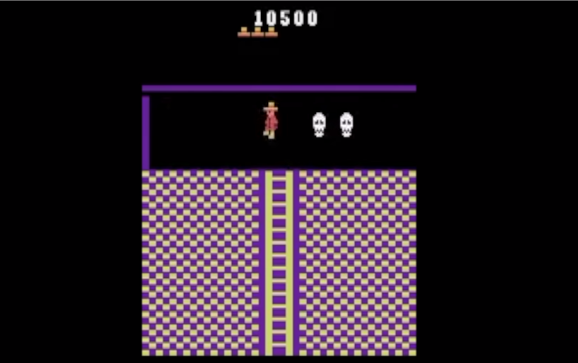
Tym razem OpenAI stworzyło system lepszy od ludzi w retro gierce Montezuma Revenge, dzięki świeżo opracowanej metodzie RND.
OpenAI jest nienastawioną na zysk organizacją z San-Francisco, która zaskarbiła sobie wsparcie wielu inwestorów, wśród których znalazł się m.in. Elon Musk. Tamtejsi naukowcy zajmują się głównie rozwojem sztucznej inteligencji, której osiągnięcia ujawniają głównie w grach komputerowych. Już teraz mają na koncie fenomenalnie spisującą się drużynę w DOTA 2, czy bratobójczą kadrę w Starcraft 2. W najnowszym projekcie zadbali o to, aby pokonać ludzi w oldschoolowej grze Montezuma Revenge z Atari 2600. Nietrudno się domyślić, że i tutaj OpenAI odniosło sukces, który wymagał jednak nowego podejścia do maszynowego uczenia się.
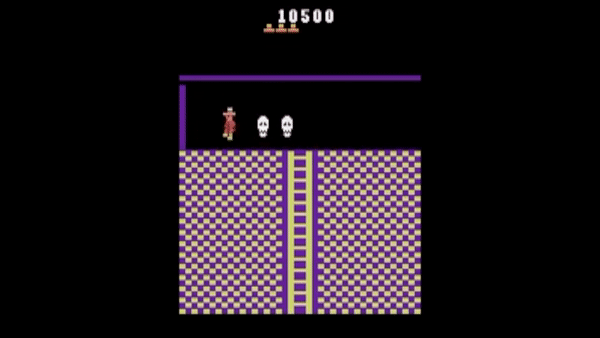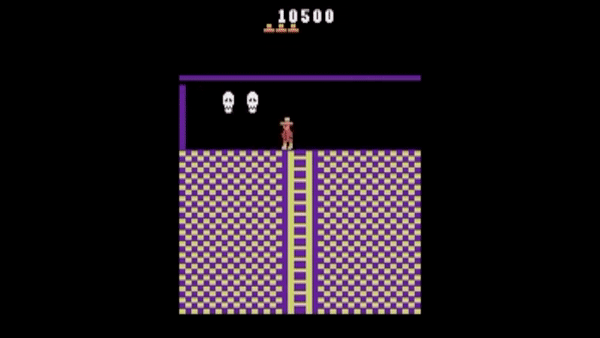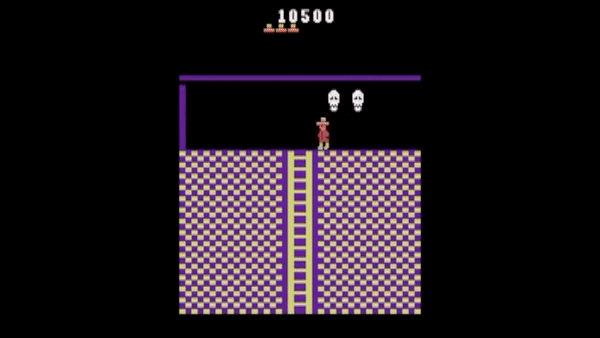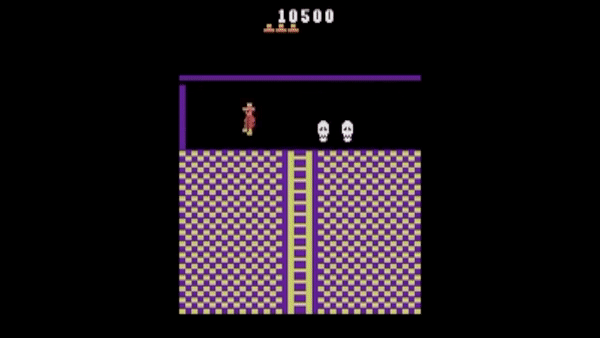
Tym jest metoda RND (Random Network Distillation), czyli w potocznym tłumaczeniu ”losowa destylacja sieci”. Ta może napędzić każdy algorytm maszynowego uczenia, który np. bazuje na systemie nagród i kar, nakierowujących poczynania agentów SI. W przeciwieństwie do tradycyjnej metody, RND wprowadza dodatkową nagrodę, opartą na przewidywaniu wyniku stałej i losowo zainicjowanej sieci neuronowej w następnym stanie. Dzięki temu SI było zachęcane do eksplorowania obszarów mapy, których odwiedzenie nie było konieczne do ukończenia gry. Wynik? Odkrycie wszystkich ukrytych pokoi w najdłuższej próbie i zdobywanie średnio 10000 punktów.

Celem RND jest więc rozwój sztucznej inteligencji, która zamiast skupiać się na osiągnięciu celu, stara się również o zrobienie tego w możliwie najlepszym stylu. Widać to po kolejnych próbach w Super Mario (odkrycie 11 poziomów i ukrytych lokacji), choć nie wypada to najlepiej przy grze w Ponga. Wtedy SI decyduje się przedłużać grę w nieskończoność.
Czytaj też: Ludzie jednak górują w DOTA 2 nad OpenAI Five
Źródło: VentureBeat