
Badacze z Carnegie Mellon University opracowali niedawno system komputerowy, który jest w stanie wygenerować animacje wyłącznie na podstawie scenariusza filmowego. Ten jest o tyle rewolucyjny, że po raz pierwszy łączy w sobie konkretne powiązanie naturalnego określenia póz, czy akcji aktorów na podstawie samych określeń.
Czytaj też: Naukowcy wykazali potencjał kwantowych systemów na usługach chmurowych
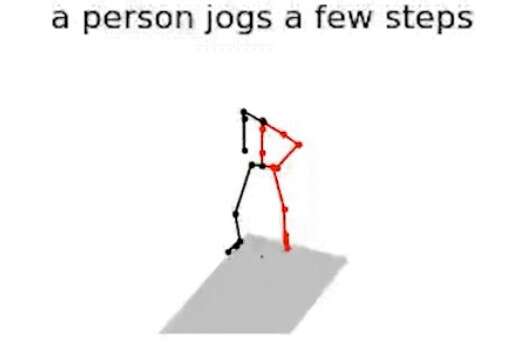
Joint Language-to-Pose (JLP2) jest właśnie tą architekturą neuronową (odłamem sztucznej inteligencji), której zaprojektowaniem zajął się Louis-Philippe Morency i Chaitanya Ahuja. Już teraz model JL2P umożliwia połączenie ze sobą określonych zdań i ruchów fizycznych, dzięki czemu może zrozumieć, w jaki sposób język jest powiązany z działaniem, gestami i ruchem aktorów.
Myślę, że jesteśmy na wczesnym etapie tych badań, ale z punktu widzenia modelowania, sztucznej inteligencji i teorii jest to bardzo ekscytujący moment. W tej chwili mówimy o animowaniu wirtualnych postaci. W końcu ten związek między językiem, a gestami może zostać zastosowany do robotów; możemy być w stanie po prostu powiedzieć robotowi-asystentowi, co chcemy zrobić.
System JL2P zostanie zaprezentowany już 19 września na Międzynarodowej Konferencji 3-D Vision w Quebec City w Kanadzie. Będzie to pokaz nie tylko prostej animacji (w stylu tej widocznej poniżej), ale też samego oprogramowania, które bazuje na metodzie nauki sieci neuronowej przez stopniowe zwiększanie poziomu trudności zadań, wykorzystując do tego nazwę akcji, prędkość, lokację, czy kierunki. Ostatecznym celem jest animowanie złożonych sekwencji z wieloma akcjami, które zachodzą jednocześnie lub w sekwencji.
Czytaj też: Xiaomi prezentuje 30 W bezprzewodowe szybkie ładowanie i pracuje nad 40 W
Źródło: Techxplore
{kind=link}